

“Never ask anyone for their predictions about the market. Just ask them what they have in their portfolio.” - Nassim Taleb
The current AI situation is very confusing for policymakers. The current state of AI is contested, and its future is unknowable. We are currently in the middle of a new paradigm; the transformer architecture has allowed us to scale up models in different ways. We can now efficiently take advantage of the massive amounts of data and compute infrastructure the internet age has gifted us. Riding these scaling curves out to their saturation point has driven rapid progress on many benchmarks, as well as resulted in massive products like chatGPT.1 However, the current paradigm has flaws and expert opinion is divided on how far it will take us, with some experts saying all the way, and others saying not much further. This uncertainty in expert opinion can be partially attributed to a measurement gap - performance on current benchmarks can sometimes translate poorly to real world impact. If we want to make good policy about AI, we need to keep this in mind. Building up state capacity in AI monitoring would allow us to have accurate real time estimates of capabilities. But monitoring is not enough; we also need to accept there is a fundamental uncertainty to how AI will develop, and prepare ourselves for many possible outcomes.
There is a fundamental uncertainty to AI advancement
Since AlexNet and the advent of deep learning, advances in AI have happened very quickly. However, the future is uncertain. Among experts, there is no consensus on how fast capabilities will advance. There is evidence that short, medium, or long timelines for AI development are feasible, depending on how bullish one is on the current paradigm.2
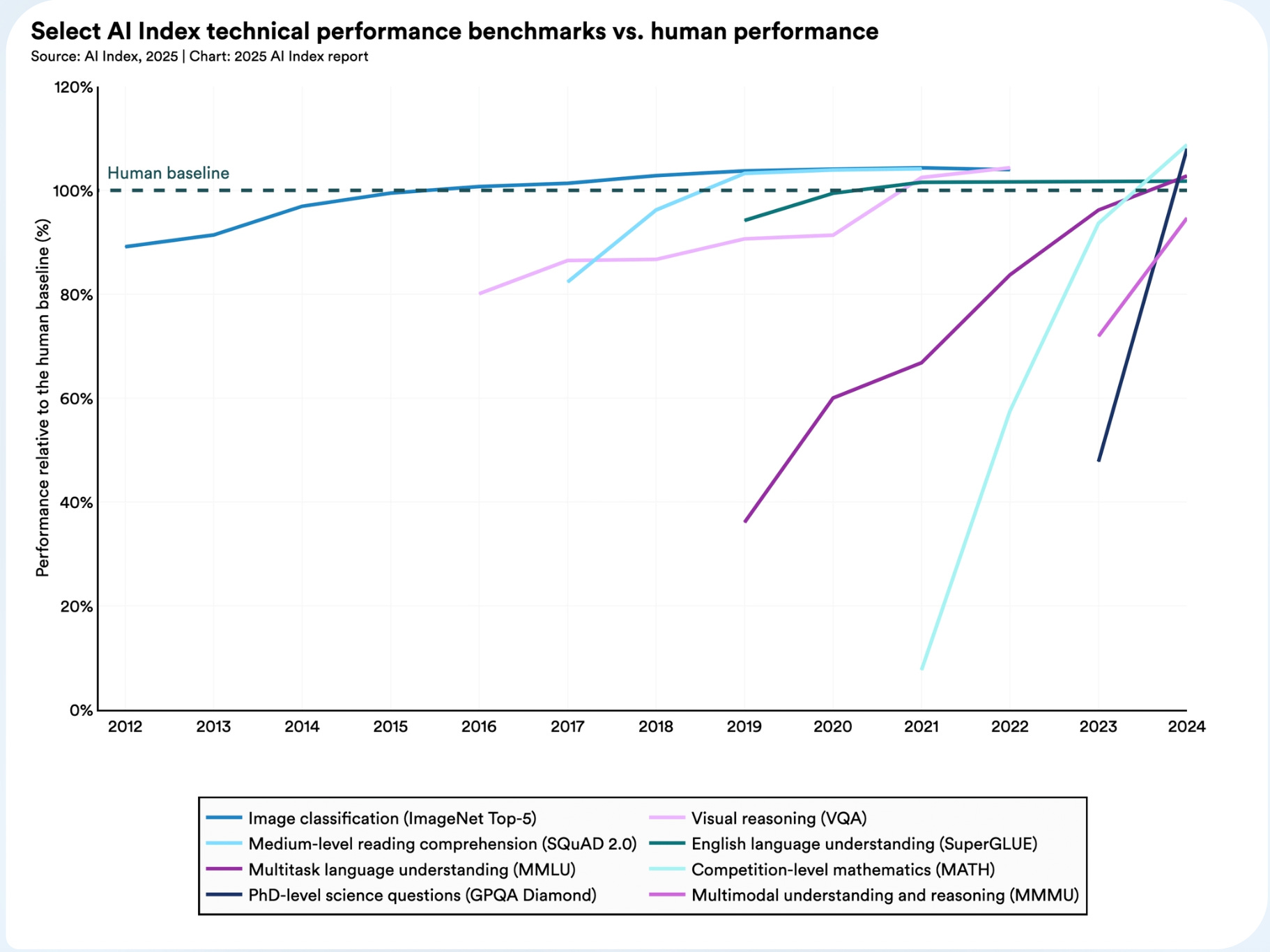
Fundamental breakthroughs in AI capabilities cannot be predicted or extrapolated. There is also a diffusion lag that means research progress doesn’t immediately lead to innovation in products. The hyper competitive market around AI may mean this is changing, at least in the case of generative AI (there is still a lag in safety constrained areas like robotics or medical devices). Now that the infrastructure is mature and we have huge competitive pressure, new advances such as reasoning models are quickly deployed. Even undercooked ideas like agents that don’t really work yet are being deployed prematurely and iterated on in public.
So over time, AI is becoming more advanced in different ways, and becoming more available. People talk about certain restrictions or regulations being effective, such as chip export restrictions. However, with recent gains in efficiency, maybe this is more of a delaying tactic than a crippling blow. Deepseek, a Chinese AI company, showed us that with technical innovation you can train a great model with second rate compute resources. AI isn’t just compute - it’s also data, and algorithms. We’re in a situation where the barrier to making powerful AI, and what it can do are both moving targets.
This makes it difficult to articulate robust policy interventions that will age well. There is a danger that overly specific regulation could be like “whack-a-mole”; you make a law that applies to a certain architecture and then it becomes obsolete or even harmful in the future. One suggestion to get around this is to regulate downstream, at the application level.3 Regulating at the application layer is a bottom up approach, and is less likely to lead to concentration of power and market dominance. For small countries like NZ, this is even more critical - if we want to stay economically competitive in the future, we need to take a cautious but optimistic approach.
The means of progress
Recent progress has been driven by scaling different aspects of AI development.
Every year, AI developers scale up training compute by ~4x and dataset size by ~2.5x. 4The primary driver of training compute growth has been investments to expand the AI chip stock, as demand has outpaced improvements in chip performance. We should be able to scale up compute until 2030 (that would be 10,000x current levels), but after that we may run into problems due to bottlenecks in data, chip production, capital, and energy.5
When people talk about scaling, they aren’t just talking about making models bigger. There are several different scaling “laws”. You can scale data quality, data size, model size, and recently, thinking time.
Performance increases logarithmically with both training resources and thinking time.6 For the non mathematically inclined, this tells us that as you put more resources into training a bigger model, or having it think longer, you get diminishing returns.
This is a concern for AI companies, but the idea is they can keep finding new things to scale, or scale existing things more intelligently. A very important aspect which has many technological diffusion implications is 'training efficiency'. We are seeing roughly 3x improvement in efficiency per year.
There is also a lot of innovation around post training. A review of post training methods found that they can lead to large performance gains for the model while requiring very little compute.
Synthetic data allows us to get arbitrarily large datasets, but is only useful for domains where the synthetic data can be formally verified and filtered for quality, such as mathematics and programming.
Reasoning models take advantage of this; Reinforcement learning is performed on the chain of thought, which induces the model to independently learn to solve problems logically through step by step reasoning.
This can lead to very impressive results; an advanced version of Google’s Gemini model was able to achieve a gold medal in the international mathematical olympiad, a math competition for the world’s smartest high school students7. Importantly, it did all in natural language, with no computer algebra system. This is genuinely impressive.
One downside of this approach is that pushing this aggressive reinforcement learning on verifiable rewards “overcooks” the model, over optimizing it along a single axis and degrading it in other ways, such as increasing its hallucination rates.8
The next wave of focus for companies is agents. These are autonomous systems, built on the idea of training current language models to iteratively use tools and receive environmental feedback as context in a loop. From what I can tell, agents are not quite there yet. Especially on open ended, complex tasks they struggle. Zvi’s take on OpenAI’s recent GPT agent release sums it up; “So far, it does seem like a substantial upgrade, but we still don’t see much to do with it.”9 However, there’s a lot of investment in them because people expect them to be very economically valuable, so this could change in the future.
Measurement gap means we are confused about the effectiveness of the current paradigm
Our timelines for AI depend on if we think we are on the right branch of the tech tree.10 Again, there is no expert consensus how far scaling generative models will take us.
A large part of the divide in expert opinion is due to what we can call the measurement gap.
Recent progress has outpaced expectations, and many widely used benchmarks have been maxed out. However, models can still be very disappointing and fail in inhuman ways. AI benchmarks are useful for measuring algorithmic progress; but this is not the same thing as progress in usefulness. There is also a problem of anthropomorphism - AI is a different type of “mind” - it is both better and worse than humans in different ways, and mapping our internal conceptions of competence onto it can get us in trouble.
Benchmarks like SWE bench show that models can sometimes complete discrete, defined tasks, but that is only one part of performing a professional job. Models are not yet capable of the parts of a job that are less well defined and require creativity, judgement, context, etc. These “glue” aspects of a job that exists between the crisp boundaries of well defined, exam like tasks are precisely the things that would be most economically transformative if they were automated. However, benchmarks struggle to capture them; how do you give someone a “numerical score” on how good they are at their job? This measurement gap leads to a policy challenge: it's hard to tell 'how good' AI really is at stuff, because there are many important aspects of capability that aren’t amenable to measurement.
Prepare for the future, don’t predict it
If we zoom out a bit, our track record isn’t great. We’ve just recently been caught flat footed by another, much less transformative technology; social media. We failed to regulate the harms because we had the best case scenario in mind only. The internet was supposed to promote democracy, self expression, and community organizing, but instead, it made us socially isolated, politically polarized, and mentally ill. By failing to plan for different outcomes of the technology, we drifted into a disaster.
We need to be proactive with AI to avoid this happening. We need to be mentally flexible and adjust our approach based on what happens instead of being ideologically tied to a certain scenario being our pet theory.
The first step is to invest in monitoring capacity that allows us good, up to date information about model capabilities. As I enumerated in my AI safety institute piece11, it is critical to figure out what’s really happening with AI, because policies that could be good in one situation could be very harmful in another.
Here’s an example; a lot of the current debate is focused on whether or not AI is a “normal” technology. Some people focused on existential risk say AI is a uniquely dangerous technology, therefore, we cannot have a hands off, innovation friendly approach like we did with the internet. If this point of view is true, it seems to imply that AI is so dangerous that countries should be advocating for a global moratorium on its development . In essence, one should take a stance of “AI nonproliferation”.
The other point of view says that although AI will be powerful, it will take time to diffuse throughout society, we will do more harm than good in seeking to avoid speculative risks through non proliferation. For example, global control implies a concentration of power. In this view, (safely) diffusing AI and regulating it at the application level empowers individuals to increase their own productivity and share in the benefits of AI, as opposed to it being used as a vector of control or abuse.
It is unclear to me which argument is true. Here’s the kicker; the policy that works best in the first situation (nonproliferation) is harmful when used in the opposite scenario. This is why we need information gathering, so we can figure out which future we are in.
Once we have monitoring capacity in place, we can start planning. The way governments traditionally do this in areas such as national security or pandemic preparedness is through a risk management technique called scenario planning.
Scenario planning was invented during the Cold War. You start with a situation with several things you can’t predict. And then you build up different scenarios, based on how those things could end up. Here’s a practical example; the UK government just released the AI 2030 Scenarios Report12. They identified five key uncertainties with regards to AI; capability, ownership concentration, safety, market penetration, and international cooperation.
They then imagined many different scenarios based on the values these variables could take. They then got rid of combinations that didn’t make sense, and grouped the rest together into 5 key scenarios. They built these scenarios up to be compelling and detailed, and thought about their implications and possible policy responses.
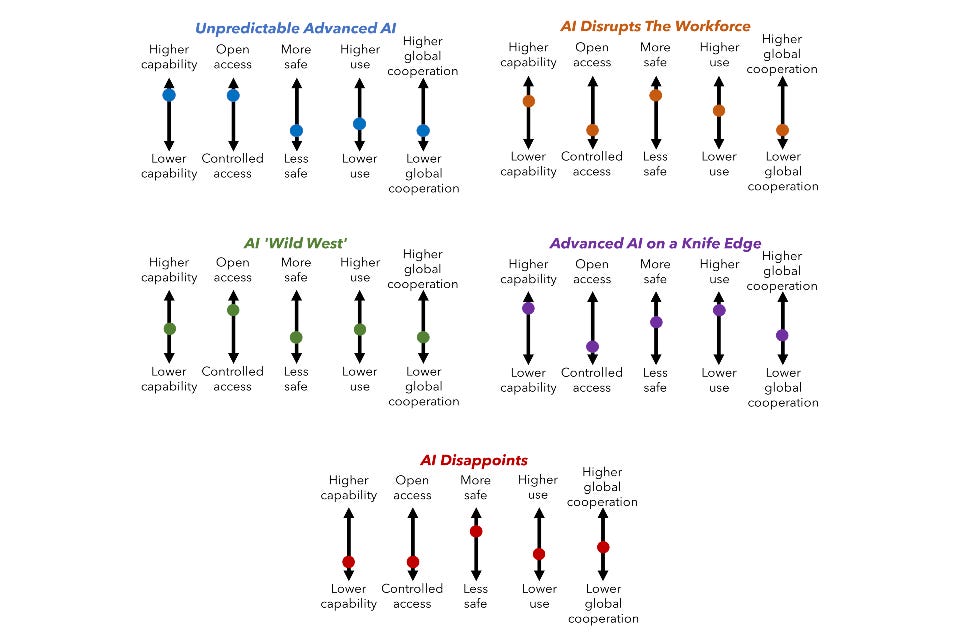
This planning is already being undertaken around the world; by governments like the UK and the US, and by non-profits and researchers. Crucially, it is not enough for us to stand by and just take the recommendations of this or that plan. In New Zealand, we need to do our own planning. Primarily, this is because we are in a unique position as a country, and other plans will not work for us. But we also have a moral duty; as a developed country, we must contribute to illuminating the path forward. Instead of trying to predict the future, we need to build strong monitoring systems and develop robust plans that allow us to thrive wherever AI takes us.
https://arxiv.org/pdf/2501.17805 International Report on AI safety, page 46
https://arxiv.org/pdf/2501.17805 International Report on AI safety, page 46
https://knightcolumbia.org/content/ai-as-normal-technology
https://arxiv.org/pdf/2501.17805 International Report on AI safety, page 46
https://arxiv.org/pdf/2501.17805 International Report on AI safety, page 16
https://arxiv.org/pdf/2501.17805 International Report on AI safety, page 43
https://deepmind.google/discover/blog/advanced-version-of-gemini-with-deep-think-officially-achieves-gold-medal-standard-at-the-international-mathematical-olympiad/
https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf

New Zealand Should Establish an AI Safety Institute

"For progress there is no cure… The only safety possible is relative, and it lies in an intelligent exercise of day-to-day judgment."
https://www.gov.uk/government/publications/frontier-ai-capabilities-and-risks-discussion-paper/ai-2030-scenarios-report-html-annex-c?utm_source=chatgpt.com#executive-summary